

AI 기반 분석
코드의 고급 분석을 위해 Noir의 AI 통합을 사용하는 방법을 알아보세요. 이 가이드는 OpenAI, xAI 및 로컬 모델과 같은 LLM 제공업체에 연결하는 데 필요한 플래그와 옵션을 다룹니다.
Noir는 클라우드 기반 서비스와 로컬 인스턴스 모두의 대규모 언어 모델(LLM)에 연결하여 코드베이스에 대한 더 깊은 수준의 분석을 제공할 수 있습니다. AI를 활용함으로써 Noir는 종종 기본적으로 지원하지 않는 언어와 프레임워크에서 엔드포인트를 식별할 수 있으며, 애플리케이션의 기능에 대한 추가적인 인사이트를 제공할 수 있습니다.
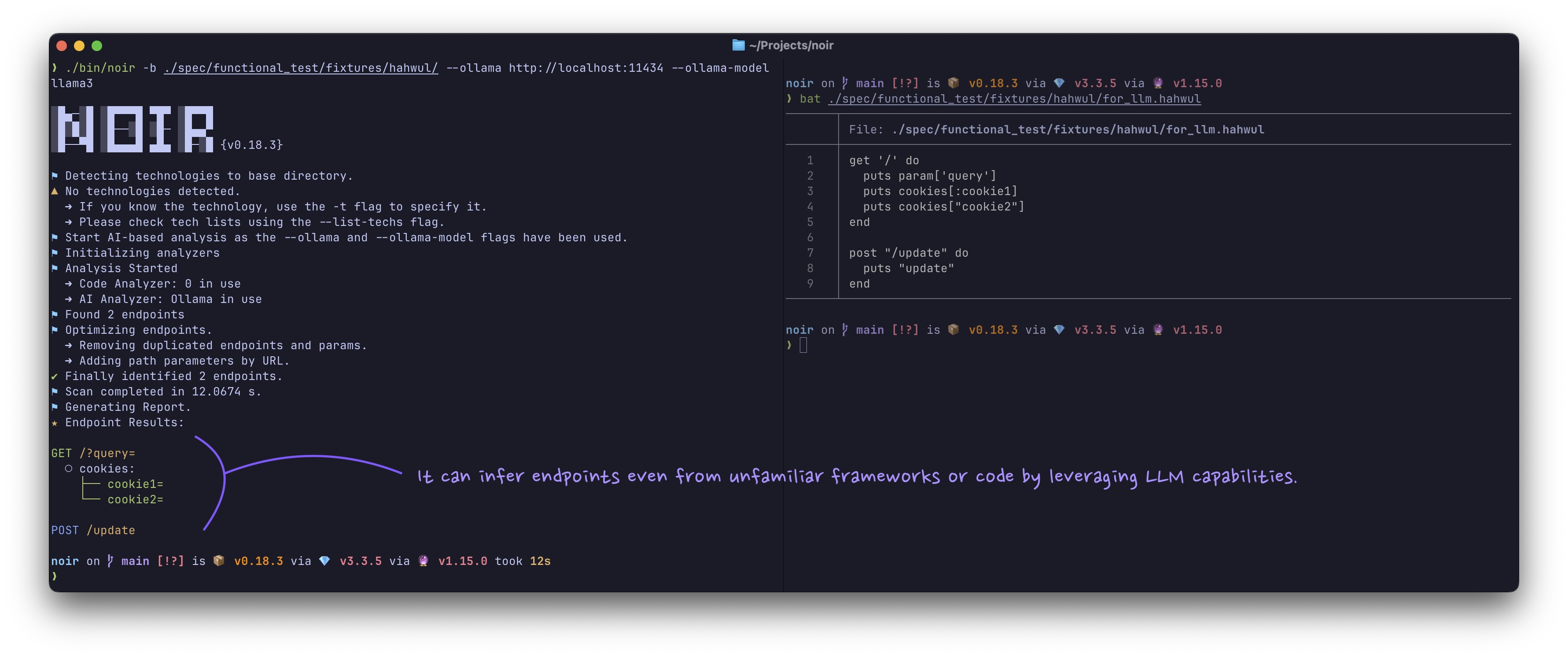
AI 통합 사용 방법
AI 기반 분석을 활성화하려면 AI 제공업체, 모델 및 API 키를 지정해야 합니다.
noir -b . --ai-provider <PROVIDER> --ai-model <MODEL_NAME> --ai-key <YOUR_API_KEY>명령줄 플래그
--ai-provider: 사용하려는 AI 제공업체입니다. 이는 사전 설정 접두사(openai또는ollama와 같은) 또는 사용자 정의 API 엔드포인트의 전체 URL일 수 있습니다.--ai-model: 분석에 사용하려는 모델의 이름입니다(예:gpt-4o).--ai-key: AI 제공업체를 위한 API 키입니다.NOIR_AI_KEY환경 변수를 사용하여 설정할 수도 있습니다.--ai-max-token: (선택사항) AI 요청에 사용할 최대 토큰 수입니다. 이는 생성된 텍스트의 길이에 영향을 줄 수 있습니다.--cache-disable: 현재 실행에서 LLM 디스크 캐시를 비활성화합니다.--cache-clear: 실행 전에 LLM 캐시 디렉터리를 비웁니다.
기본적으로 Noir는 AI 응답을 디스크에 캐시하여 반복 분석 속도를 높이고 비용을 줄입니다. 필요 시 위 캐시 플래그를 사용해 캐시를 비활성화하거나 사전 정리할 수 있습니다.
지원되는 AI 제공업체
Noir는 다음 AI 제공업체를 지원합니다:
OpenAI
noir -b . --ai-provider openai --ai-model gpt-4o --ai-key YOUR_OPENAI_API_KEYxAI (Grok)
noir -b . --ai-provider xai --ai-model grok-beta --ai-key YOUR_XAI_API_KEYOllama (로컬)
로컬에서 Ollama를 실행하는 경우:
noir -b . --ai-provider ollama --ai-model llama3.2 --ai-key ""vLLM
noir -b . --ai-provider vllm --ai-model microsoft/DialoGPT-medium --ai-key ""LM Studio
로컬 LM Studio 인스턴스의 경우:
noir -b . --ai-provider lmstudio --ai-model local-model --ai-key lm-studioAI 분석의 이점
AI 통합을 사용할 때 다음과 같은 이점을 얻을 수 있습니다:
- 확장된 언어 지원: Noir가 기본적으로 지원하지 않는 언어와 프레임워크에서 엔드포인트 발견
- 향상된 정확도: AI가 복잡한 코드 패턴과 동적 엔드포인트를 식별하는 데 도움
- 컨텍스트 이해: AI가 코드의 맥락을 더 잘 이해하여 더 정확한 분석 제공
모범 사례
- 적절한 토큰 제한을 설정하여 비용과 성능의 균형을 맞추세요
- 민감한 코드의 경우 로컬 AI 모델 사용을 고려하세요
- AI 분석 결과를 정적 분석 결과와 함께 검토하여 포괄적인 보안 평가를 수행하세요
AI 기반 분석 작동 방식
Noir의 AI 통합은 지능형 파일 필터링, 최적화된 번들링, 응답 캐싱, 엔드포인트 최적화를 결합한 정교한 워크플로우를 통해 포괄적인 분석 결과를 제공합니다.
flowchart TB
Start([AI 분석 시작]) --> InitAdapter[LLM 어댑터 초기화]
InitAdapter --> ProviderCheck{제공자 타입?}
ProviderCheck -->|OpenAI/xAI/등| GeneralAdapter[General Adapter<br/>OpenAI 호환 API]
ProviderCheck -->|Ollama/Local| OllamaAdapter[Ollama Adapter<br/>컨텍스트 재사용]
GeneralAdapter --> FileSelection
OllamaAdapter --> FileSelection
FileSelection[파일 선택] --> FileCount{파일 개수?}
FileCount -->|≤ 10개 파일| AnalyzeAll[모든 파일 분석]
FileCount -->|> 10개 파일| LLMFilter[LLM 기반 필터링]
LLMFilter --> CacheCheck1{캐시 있음?}
CacheCheck1 -->|예| UseCached1[캐시된 필터 사용]
CacheCheck1 -->|아니오| FilterLLM[FILTER 프롬프트로<br/>LLM 호출]
FilterLLM --> StoreCache1[캐시에 저장]
UseCached1 --> TargetFiles
StoreCache1 --> TargetFiles
TargetFiles[선택된 대상 파일] --> BundleCheck{대량 파일 및<br/>토큰 제한?}
AnalyzeAll --> BundleCheck
BundleCheck -->|예| BundleMode[번들 분석 모드]
BundleCheck -->|아니오| SingleMode[단일 파일 모드]
BundleMode --> CreateBundles[토큰 제한 내에서<br/>파일 번들 생성]
CreateBundles --> ParallelBundles[번들 동시 처리]
ParallelBundles --> BundleLoop{각 번들마다}
BundleLoop --> CacheCheck2{캐시 있음?}
CacheCheck2 -->|예| UseCached2[캐시된 분석 사용]
CacheCheck2 -->|아니오| BundleLLM[BUNDLE_ANALYZE<br/>프롬프트로 LLM 호출]
BundleLLM --> StoreCache2[캐시에 저장]
UseCached2 --> ParseEndpoints1
StoreCache2 --> ParseEndpoints1
ParseEndpoints1[응답에서<br/>엔드포인트 파싱] --> BundleLoop
BundleLoop -->|완료| Combine
SingleMode --> FileLoop{각 파일마다}
FileLoop --> CacheCheck3{캐시 있음?}
CacheCheck3 -->|예| UseCached3[캐시된 분석 사용]
CacheCheck3 -->|아니오| AnalyzeLLM[ANALYZE 프롬프트로<br/>LLM 호출]
AnalyzeLLM --> StoreCache3[캐시에 저장]
UseCached3 --> ParseEndpoints2
StoreCache3 --> ParseEndpoints2
ParseEndpoints2[응답에서<br/>엔드포인트 파싱] --> FileLoop
FileLoop -->|완료| Combine
Combine[모든 엔드포인트 결합] --> LLMOptCheck{LLM 최적화<br/>활성화?}
LLMOptCheck -->|예| FindCandidates[최적화 후보 찾기]
FindCandidates --> OptLoop{각 후보마다}
OptLoop --> OptimizeLLM[OPTIMIZE 프롬프트로<br/>LLM 호출]
OptimizeLLM --> ApplyOpt[엔드포인트에<br/>최적화 적용]
ApplyOpt --> OptLoop
OptLoop -->|완료| FinalResults
LLMOptCheck -->|아니오| FinalResults[최종 최적화 결과]
FinalResults --> End([종료])
style Start fill:#e1f5e1
style End fill:#e1f5e1
style LLMFilter fill:#fff4e1
style FilterLLM fill:#e1f0ff
style BundleLLM fill:#e1f0ff
style AnalyzeLLM fill:#e1f0ff
style OptimizeLLM fill:#e1f0ff
style CacheCheck1 fill:#ffe1e1
style CacheCheck2 fill:#ffe1e1
style CacheCheck3 fill:#ffe1e1
style UseCached1 fill:#e1ffe1
style UseCached2 fill:#e1ffe1
style UseCached3 fill:#e1ffe1
주요 구성 요소
1. LLM 어댑터 레이어
Noir는 여러 LLM 제공자를 지원하는 제공자 독립적인 어댑터 패턴을 사용합니다:
- General Adapter: OpenAI 호환 API용 (OpenAI, xAI, Azure, GitHub Models 등)
- Ollama Adapter: 성능 향상을 위한 서버 측 컨텍스트 재사용 기능이 있는 전문 어댑터
2. 지능형 파일 필터링
많은 파일(>10개)이 있는 프로젝트를 분석할 때 Noir는 LLM을 사용하여 엔드포인트를 포함할 가능성이 있는 파일을 지능적으로 필터링합니다:
- FILTER 프롬프트와 함께 파일 경로 목록을 LLM에 전송
- LLM이 잠재적 엔드포인트 파일 식별
- 분석 시간 및 비용 절감
3. 번들 분석
대규모 코드베이스의 경우 Noir는 여러 파일을 번들로 묶어 효율성을 극대화합니다:
- 각 파일의 토큰 사용량 추정
- 모델 토큰 제한 내에서 번들 생성 (80% 안전 마진 적용)
- 속도를 위해 번들을 동시 처리
- BUNDLE_ANALYZE 프롬프트를 사용하여 번들의 모든 파일에서 엔드포인트 추출
4. 응답 캐싱
모든 LLM 응답은 성능 향상과 비용 절감을 위해 디스크에 캐시됩니다:
- 캐시 키: (제공자 + 모델 + 작업 + 형식 + 페이로드)의 SHA256 해시
- 캐시 위치:
~/.local/share/noir/cache/ai/(또는NOIR_HOME설정 시) - 변경되지 않은 코드의 즉시 재분석 가능
--cache-disable로 비활성화하거나--cache-clear로 삭제 가능
5. LLM 옵티마이저
엔드포인트 결과를 개선하는 선택적 후처리 단계:
- 비표준 패턴 식별 (와일드카드, 특이한 명명 등)
- URL 및 파라미터 이름 정규화
- RESTful 규칙 적용
- 전반적인 엔드포인트 품질 향상